Making Mora By Reading Mora
I know what you’re thinking: Who cares?
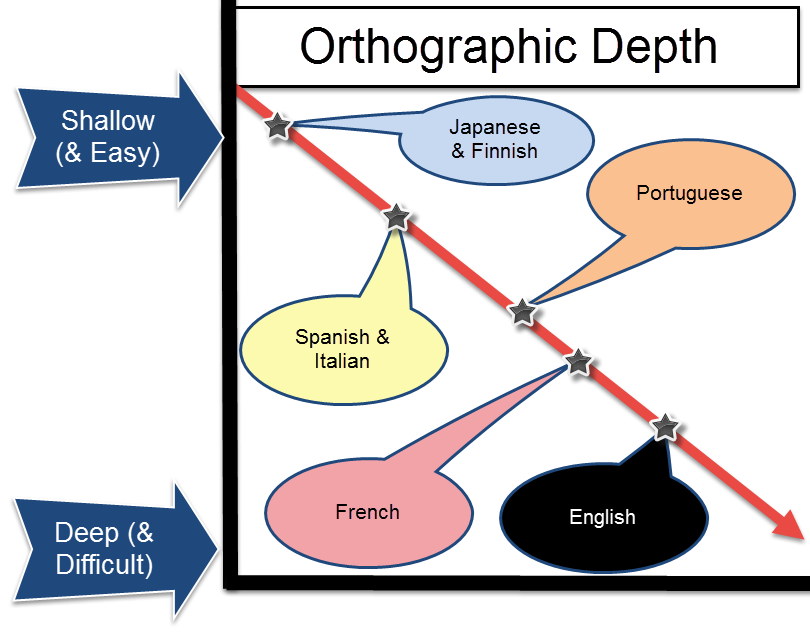
The thing is, knowing first that Japanese sounds are divided into mora, then knowing that these mora are represented by Japanese characters, gives insight into why Japanese is such a simple language to pronounce. Or, to get technical, this illustrates the shallow orthographic depth of the Japanese language.
Say what?
“Orthographic depth” is just a fancy way to say “How much words sound like they’re spelled.”
A language with a deep orthographic depth is difficult to read phonetically, as many of the sounds will vary. English is like this, and it’s a nightmare for foreign learners. For example, how many of these words sound the same, or different…
- Query, very
- Tow, vow, row, bow, bow
- Monkey, donkey
- Grasp, wasp
- Though, through, plough, dough, cough
Students often ask me, “Why is English spelling so complicated?” I answer by sweating nervously. Or saying, “Because, of course.” Or, “Shut up, you.”
Honestly, I feel so bad for people trying to learn English sometimes.
Languages with a shallow orthographic depth are easy to read aloud because words are almost always pronounced as they are written. For example, Spanish has a relatively shallow orthographic depth. If you know the basics of pronouncing Spanish syllables (which can vary by regions), then you should be able to read almost any passage aloud.
And, lucky us, Japanese also has an extremely shallow orthographic depth. Word sounds are always pronounced exactly as they are spelled. (Well, 99% of the time.) So if you can read the characters, then you should be able to read almost any passage aloud with relative accuracy.
Here are a couple of scary charts taken from Wikipedia (I have added romaji under each hiragana character; also, each hiragana character is linked to the Wikipedia page with details on that particular character):
|
IPA |
-a |
-i/ʲi |
-ɯ̥ |
-e |
-o (-o) |
-ʲa (-ya) |
-ʲu |
-ʲo |
|
'- |
a |
い |
う |
え |
お |
|||
|
k- |
か |
き |
く |
け |
こ |
きゃ |
きゅ |
きょ |
|
g- |
が |
ぎ |
ぐ |
げ |
ご |
ぎゃ |
ぎゅ |
ぎょ |
|
s- |
さ |
す |
せ |
そ |
||||
|
ɕ- |
しゃ |
し |
しゅ |
しょ |
||||
|
z- |
ざ |
ず |
ぜ |
ぞ |
||||
|
dʑ- |
じゃ |
じ |
じゅ |
じょ |
||||
|
t- |
た |
て |
と |
|||||
|
tɕ- |
ちゃ |
ち |
ちゅ |
ちょ |
||||
|
t͡s- |
つ |
|||||||
|
d- |
だ |
で |
ど |
|||||
|
n- |
な |
に |
ぬ |
ね |
の |
にゃnya |
にゅ |
にょ |
|
h- |
は |
ひ |
へ |
ほ |
||||
|
ç- |
ひゃ |
ひゅ |
ひょ |
|||||
|
ɸ- |
ふ |
|||||||
|
p- |
ぱ |
ぴ |
ぷ |
ぺ |
ぽ |
ぴゃ |
ぴゅ |
ぴょ |
|
b- |
ば |
び |
ぶ |
べ |
ぼ |
びゃ |
びゅ |
びょ |
|
m- |
ま |
み |
む |
め |
も |
みゃ |
みゅ |
みょ |
|
j- |
や |
ゆ |
よ |
|||||
|
ɺ- |
ら |
り |
る |
れ |
ろ |
りゃ |
りゅ |
りょ |
|
β̞- |
わ |
|
special mora |
ɴ- |
|
|
t̚ - |
っ |
|
|
zu |
づ ヅ dzu Although the romaji version includes a “d,” for this character, you don’t actually need to pronounce it. Just saying ず (zu) is quite common. |
|
|
dʑi |
ぢ ヂ dzi Although the romaji version is written with “dz,” this character is usually just pronounced the same as じ (ji). |
|
|
ː- |
ー |
|
|
[o] |
を ヲ The same pronunciation as お / オ (o), but often written in romaji as wo. (used almost exclusively as a particle, the katakana form (ヲ) is almost never used.) |